19157628936
lx@jinglianwen.com
时间:2024-05-07 14:36:30

作者:极悦注册科技

浏览: 次
机器学习(ML)和人工智能(AI)逐渐融入我们的日常生活。机器学习系统中的偏见引起了机器学习和人工智能的发展。
尽管AI和ML可以提供许多好处,但程序中的偏见可能会导致模型产生有害的结果。当算法由于机器学习过程中的错误假设而产生偏见的结果时,就会出现偏差。
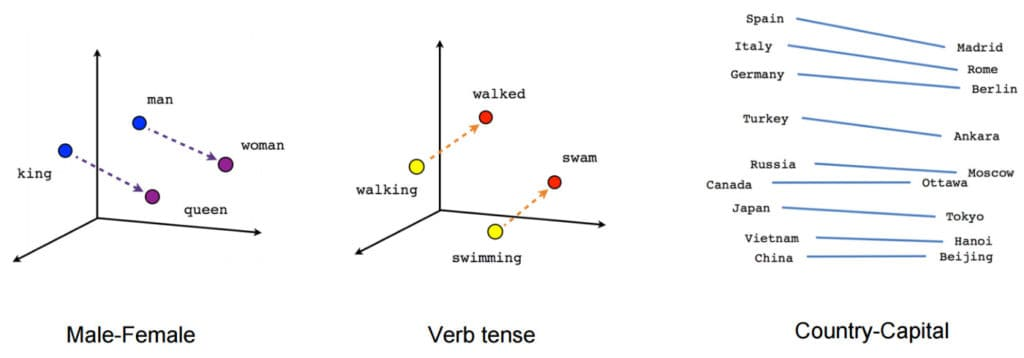
词嵌入
词嵌入是词关联的自然语言处理问题。在算法术语中,这些是在向量空间中相近的词,因此预期具有相似的含义。
样本偏差/选择偏差
样本偏差或选择偏差发生在使用的数据集不够大或没有足够的代表性来教导系统时。如果对人们在选举中没有投票的原因进行调查,并且被调查的整个群体都在离开购物中心,理论上会排除不一定来自该地区的人,这可能会导致所选样本出现偏差。
排除偏差
排除偏差发生在有价值的数据被删除时,因为它被认为是不重要的。
测量偏差
当由于数据输出中的人为违规行为导致训练模型的测量和精度出现问题时,就会出现这种偏差。
算法偏差
如果机器学习模型中存在缺陷,则可能会出现算法偏差,其中它会选择不正确的模式并重新应用它。
确认偏差/观察者偏差
确认偏差导致倾向于处理或寻找与一个人当前持有的信念一致的数据或模型结果。产生的结果和输出会加强一个人的确认偏差,从而导致较差的结果。
1. 数据集选择
虽然AI和ML偏差很难缓解,但有一些预防性技术可以帮助减少这个问题。识别偏差的第一个挑战是了解一些机器学习算法如何从训练数据中概括学习。用于模型的数据集的选择需要代表现实世界。如果数据集仅包含人口的一个子集,则结果将发生变化。
2. 多元化团队
多元化是开始消除偏见的最佳方式。通过产生全面的、有代表性的数据集,使团队多样化可以对机器学习模型产生重大的积极影响。拥有一个多元化的开发团队可以帮助减轻数据集架构中的偏见,拥有一个多元化的标注器团队可以帮助减少分类法应用于数据的偏见。
3. 减少排除偏差
为了帮助减少AI中的排除偏差,特征选择是关键。在开发质量模型时,从模型中过滤掉不相关或冗余的数据点很重要。此特定任务排除了没有足够方差来解释结果变量的数据点。
4. 人工参与
解决人工智能偏见的另一种方法是让人工参与进来,以主动识别意外偏见的模式。这减少了系统中的缺陷,创建了一个更加中立的模型。组织还应制定指导方针和程序,以识别和减轻数据集中的潜在偏差。记录发生的偏见案例,概述如何发现偏见,并传达这些问题有助于确保过去的偏见事件不再重复。
5. 代表性数据
在为模型训练聚合数据之前,组织应该了解代表性数据是什么样的。人口的实质和所用数据的特征应等同于偏差最小的数据集。除了识别数据集中的潜在偏差外,组织还应该记录他们的数据选择和清理方法,以消除根本原因。
人工智能在自动化繁琐的任务、改进决策和促进更大的自由方面具有巨大潜力。随着模型的改进和我们对它们的依赖增加,我们必须保持警惕,以确保偏见不会破坏模型的功效或腐蚀我们对它们的信任。
在模型开发的每个阶段,从模型架构到数据收集到数据标注,通过迭代测试、分析和再培训,都必须考虑潜在的偏差。定制的数据标注解决方案和极悦注册数据标注平台可以帮助确保AI发挥其作为进步推动者的潜力。
