19157628936
lx@jinglianwen.com
时间:2024-04-24 11:48:11

作者:极悦注册科技

浏览: 次
什么是机器学习中的文本标注?
简单地说,机器学习 (ML) 中的文本标注是为数字文件或文档及其内容分配标签的过程。
文本标注数据集可以实现其将文本块从一种源语言自动翻译成目标语言的预期功能。例如,可以训练这些模型将中文普通话的句子自动翻译成美式英语。
现代翻译工具利用循环神经网络(RNN) 作为其模型来执行其翻译功能。它拥有一个编码器,旨在将句子或段落转换为数字序列,通常称为思想向量或意义向量。同时,它还有一个解码器,可以处理这些数字序列并将其转换为目标语言的翻译文本块。这也称为编码器-解码器架构,它有效地模仿了人类如何进行自然翻译。
如上所述,训练此类模型需要带有标注文本标注的数据集。
带有文本标注的数据集通常包含突出显示或带下划线的关键文本片段,以及其边缘周围的标注。
标注文本的过程涉及有意与数字上下文数据交互的任何操作。请记住,这是为了增强读者对文本的理解。因此,在标注数据集时,您应该主要关注关键区域,这些区域可以使人类读者或机器更快、更轻松地理解、索引文本并将其存储在数据库中以供以后使用。
1.实体标注
实体标注是为您的ML和DL模型生成训练数据集的过程。主要用于开发聊天机器人应用程序,这是在文本中定位、提取和标记实体的过程。
2.命名实体识别( NER )

这是一种用专有名称标注实体的方法。这也称为实体提取、分块和识别。用于此类文本标注的常见类别包括组织名称、位置、人员、数值、月份或时间和星期几等。
关系抽取
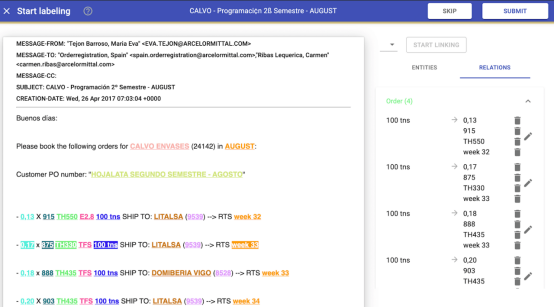
这是链接实体以更好地理解文本结构和实体之间关系的过程。在此示例中,目的是了解客户订单:更具体地说,是为了能够识别此电子邮件中包含的4个子订单。
词性标注
这是文本数据中语音的功能元素被标注的地方。这些通常是形容词、名词、副词、动词等。这种类型的文本标注最常见的用例是情感分析和分类。
文本分类
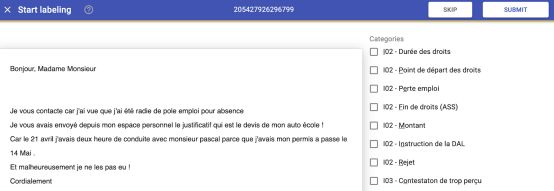
文本分类是使用单个标签标注整个正文或文本行的过程。这是将类别和标签分配给文本行或文本块中的上下文数据的地方。这通常用于标记主题、检测垃圾邮件、分析意图和情绪情绪。
情感标注
带有情感标注的文本数据用于训练NLP中机器学习任务的数据集。由于有时甚至人类也很难手动猜测文本消息或电子邮件背后的真实情感,因此这是NLP、ML 和DL中的一个具有挑战性的领域。
实体标注
实体标注是在文本数据中标注某些实体的过程。这通常用于改进与搜索相关的功能和用户体验。
极悦注册科技是AI基础数据行业的供应商,自研数据标注平台,涵盖大部分主流标注工具,支持自然语言处理:OCR转写、文本信息抽取、NLU语句泛化、词性标注、机器翻译、情感判断、意图判断、指代消解、槽位填充等多类型文本标注。
