19157628936
lx@jinglianwen.com
时间:2023-12-22 11:45:14

作者:极悦注册科技

浏览: 次
本文来自微信公众号”新智元”,作者:编辑部,极悦注册科技经授权发布。
 编辑
编辑
【新智元导读】就在昨天,百川智能正式发布Baichuan2-Turbo系列API,192K的超长上下文窗口+搜索增强知识库,解决了困扰行业已久的大模型商用落地难问题。
大模型之战的战场格局,现在基本已经划定。截至今天,全国已经有了200多个大模型,未来新模型的增量和增速将持续放缓,应用侧的比拼会愈发激烈。但一些公认的难题,却仍未解决,比如幻觉、垂直领域知识难获取、数据时效性不够、无法预测的数据集、分词器依赖、高推理延迟、有限的上下文长度、微调开销成本等等。在这种情况下,该如何破局?百川智能给出的答案是——搜索增强是大模型应用的关键,大模型+搜索是大模型落地应用的完整技术栈。为此,百川智能打造了全新的搜索增强知识库,以及基于搜索增强的Turbo系列API——Baichuan2-Turbo-192K和Baichuan2-Turbo。基于此,企业可以直接通过API,私人定制一套更完整、高效的智能解决方案。
 点击添加图片描述(最多60个字)编辑
点击添加图片描述(最多60个字)编辑一大波体验来袭
API的完整体验虽然很难展现,但我们可以通过百川智能官网的模型管中窥豹的感受搜索增强带来的体验升级。现在,你可以直接甩给Baichuan2-Turbo-192K五个公众号文章的链接 ,让它总结出这些爆款文章的共性。把18页28k的特斯拉22年第四季度财报会议总结拖进Baichuan2-Turbo-192K,可以让它一次性输出会议纪要,包括财务业绩和市场需求、产品和技术发展、企业战略和未来规划等等。长达51k的商品房买卖合同,出卖人、买受人、建面、价格等重要元素,可以按JSON格式输出。连申请CS PhD,都可以直接把三个学校的官网地址发给它,Baichuan2-Turbo-192K会快速整理出申请Stanford 、CMU、MIT CS博士的具体要求。Baichuan2-Turbo-192K可以最多上传20个文件,每个最多50M。相比之下,Claude最多能传5个文件,每个文件最多10M。
 点击添加图片描述(最多60个字)编辑
点击添加图片描述(最多60个字)编辑 点击添加图片描述(最多60个字)编辑
点击添加图片描述(最多60个字)编辑 点击添加图片描述(最多60个字)编辑
点击添加图片描述(最多60个字)编辑 点击添加图片描述(最多60个字)编辑
点击添加图片描述(最多60个字)编辑 点击添加图片描述(最多60个字)编辑
点击添加图片描述(最多60个字)编辑LLM商业落地,为什么那么难
自从ChatGPT问世以来,大模型已经红火了整整一年。但在商业落地这块,却还没有实现非常理想的效果。至于原因何在,我们不妨先更全面地了解一下「大模型」落地应用,到底是什么样的。今年11月,OpenAI著名科学家Andrej Karpathy提出了一种全新的理念——「大模型操作系统」。无独有偶,百川智能也有类似的认知,认为大模型时代的计算机主要包含以下几个部分:其中,大模型类似于「CPU」,通过预训练将知识内化在模型内部,然后根据用户的Prompt生成结果;上下文窗口可以看做是「内存」,存储了当下正在处理的文本;互联网信息与企业知识库则共同构成了这个系统的「硬盘」。当我们把它类比成最常见的计算机之后,商业化难的原因就显而易见了。
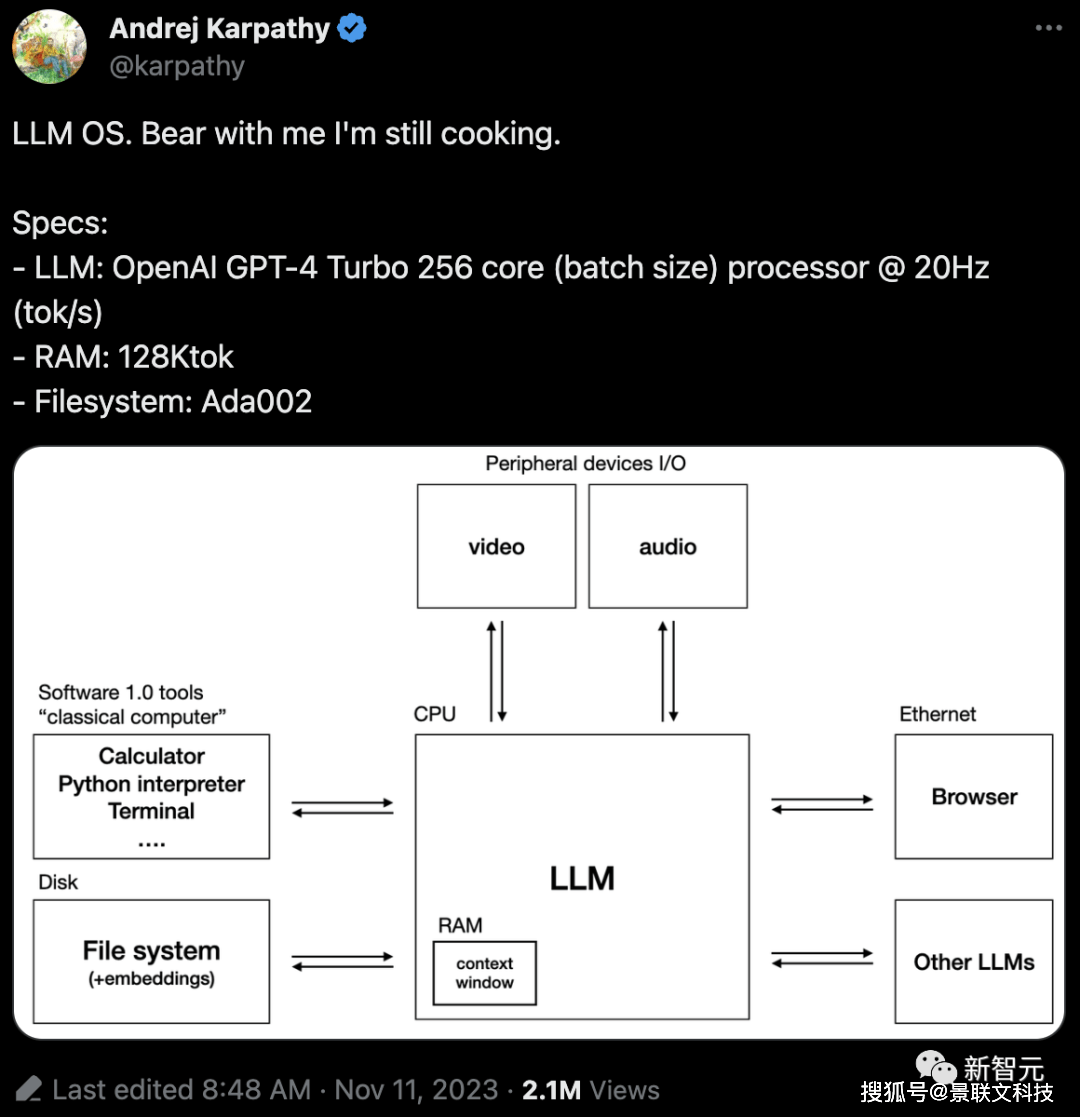 点击添加图片描述(最多60个字)编辑
点击添加图片描述(最多60个字)编辑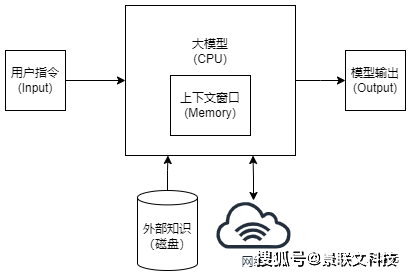 点击添加图片描述(最多60个字)编辑
点击添加图片描述(最多60个字)编辑作为CPU的大模型基于Transformer架构打造,是一种在海量数据上预训练的概率预测模型,以参数的形式将知识内化在模型内部,道不清说不明,而且通用大模型在预训练过程中它给长尾知识分配的权重比较小。对于一些非常重要但数据量很小的知识,它虽然也会内化到模型中,但是在输出时并不会给太大的权重,因此存在幻觉、时效性差、专业知识不足等先天缺陷。而互联网信息与企业知识库存在「硬盘」里,如果大模型既没有在训练时学会,又不能随时访问,那么就一定会出现专业知识的空白。
大模型+搜索增强,是完整技术栈
对于商用大模型来说,最重要的就是去解决企业的问题。而要满足千行百业的需求,模型就必须要学会这些垂直领域的专业知识。在商业化初期,厂商为了解决通用大模型领域知识匮乏的问题,各种行业大模型层出不穷。然而,新的问题又随之而来——此外,大部分企业数据都是结构化的数据,模型无法准确记忆,并不适合用来微调。
 点击添加图片描述(最多60个字)编辑
点击添加图片描述(最多60个字)编辑为解决传统方法的缺陷,不管是学界还是业界,都认为长上下文窗口和向量数据库是两种更好的路径。在学术研究领域,主要的研究方向是「知识注入」和「知识利用」,让LLM和外部知识相结合来缓解问题。多数人比较熟悉的是,2021年OpenA发布的WebGPT,可以让GPT-3通过浏览引擎来获取外部知识;Meta提出的CoVe(验证链)的提示工程方法,可以让模型访问外部数据库来验证问题。在产业领域,开源RAG生态最典型的代表便是LangChain、Lamma Index,通过提供专门构建RAG应用程序的组件,包括分割器、数据库等等,方便了开发者构建应用。OpenAI首届开发者大会上,曾重磅发布了自家的RAG产品Retrieval检索工具——OpenAI Assistants API,更是打破了对向量数据库的限制。此外,亚马逊云科技此前推出了OpenSearch Serverless向量引擎工具,为用户提供了一种简单、可扩展且高性能的相似性搜索功能,赋能生成式AI落地。就在最近,微软Azure也推出了企业级解决方案——GPT-RAG。让用户可以直接利用现有模型处理最新的数据。期间不仅无需进行繁琐的微调,而且还能确保回应的准确性,大大简化了大语言模型在企业中的应用整合过程。在此基础上,百川智能更进一步,不仅将向量数据库升级为搜索增强知识库,极大提升了大模型获取外部知识的能力;而且还把搜索增强知识库和超长上下文窗口结合,让模型可以链接全部企业知识库以及全网信息。这种方法既能为企业节省巨大成本,还能够更好地实现垂直领域知识的沉淀,让专有知识库能够真正成为企业不断增值的资产。百川智能表示,这种「长窗口模型+搜索增强」的方式,将能够替代绝大部分的企业个性化微调,解决99%企业知识库的定制化需求。由此,商用落地的种种问题,就被一一击破了!随着幻觉和时效性的问题得到解决,大模型的可用性也得到了有效提升,从而更好为诸如金融、政务、司法、教育等行业的智能客服、知识问答、合规风控、营销顾问等场景提供加持。同时,搜索增强相比微调,在提升可用性的同时还显著降低了应用成本,让更多中小企业也能够享受到大模型带来的变革。
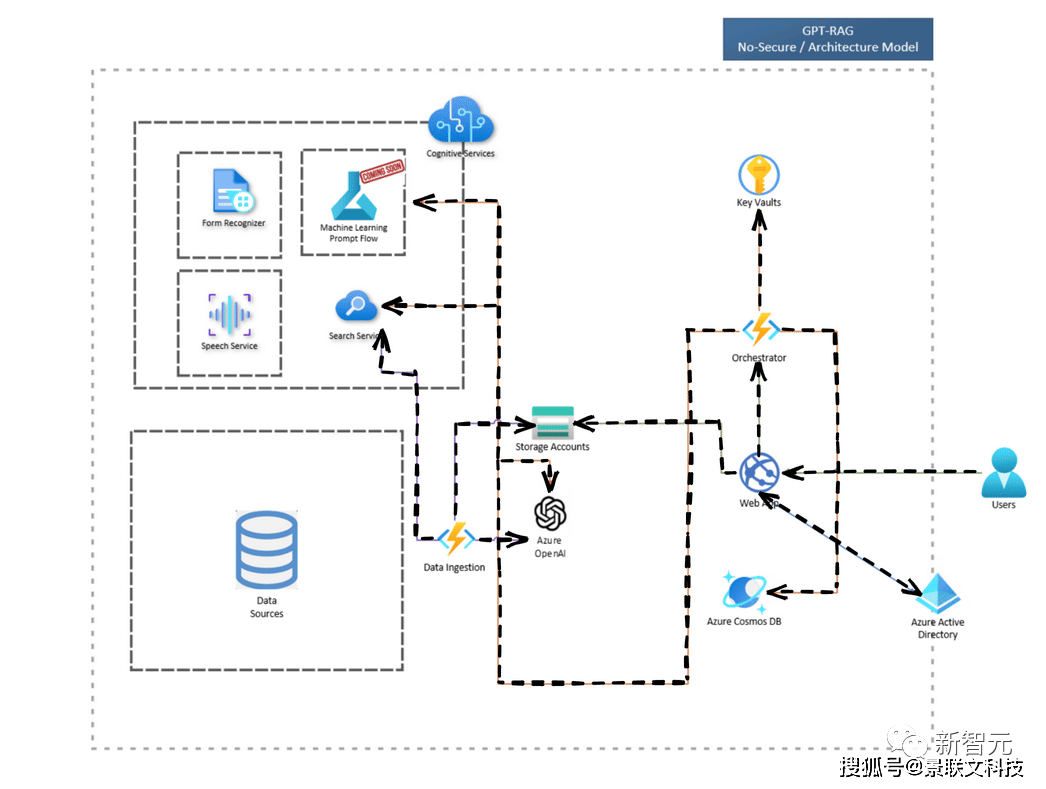 点击添加图片描述(最多60个字)编辑
点击添加图片描述(最多60个字)编辑 点击添加图片描述(最多60个字)编辑
点击添加图片描述(最多60个字)编辑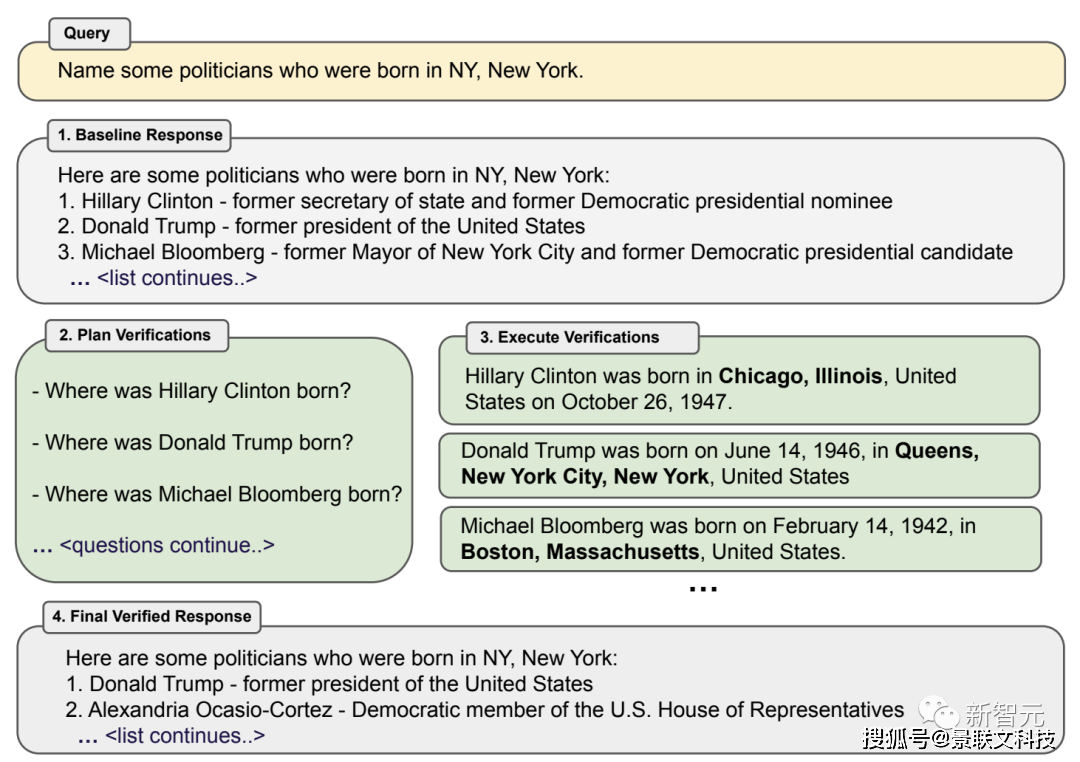 点击添加图片描述(最多60个字)编辑
点击添加图片描述(最多60个字)编辑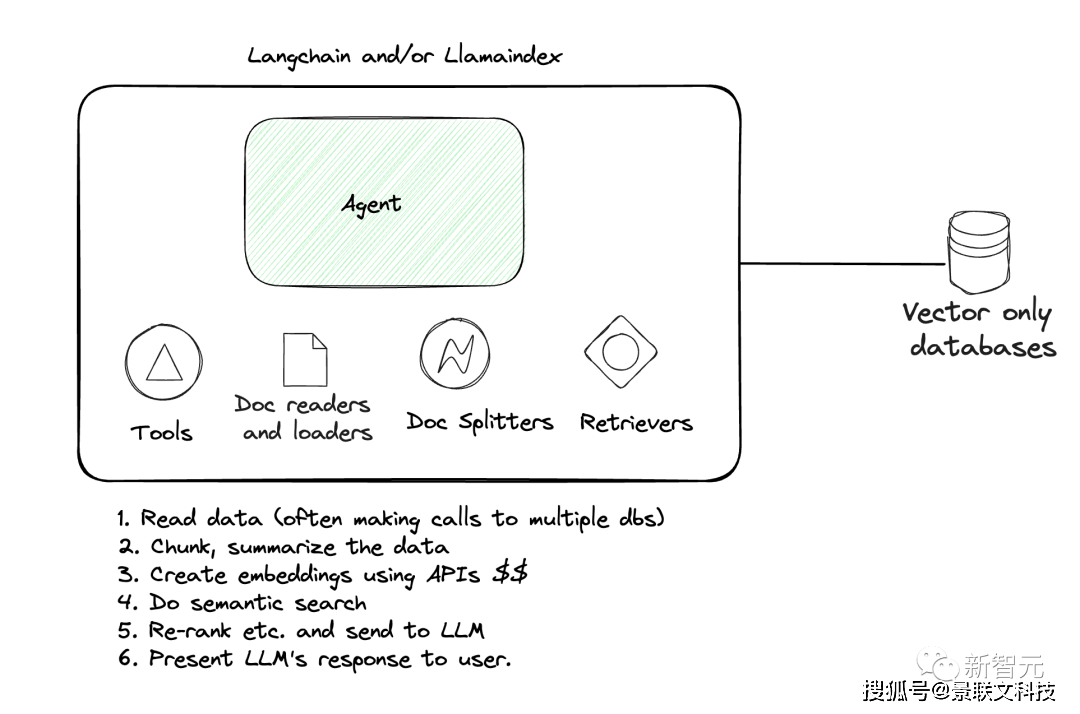 点击添加图片描述(最多60个字)编辑
点击添加图片描述(最多60个字)编辑多项创新突破,攻克搜索增强两大技术难点
不过,要实现搜索增强,必须解决两个难题。
 点击添加图片描述(最多60个字)编辑
点击添加图片描述(最多60个字)编辑难点1:如何让搜索引擎理解用户复杂的提示
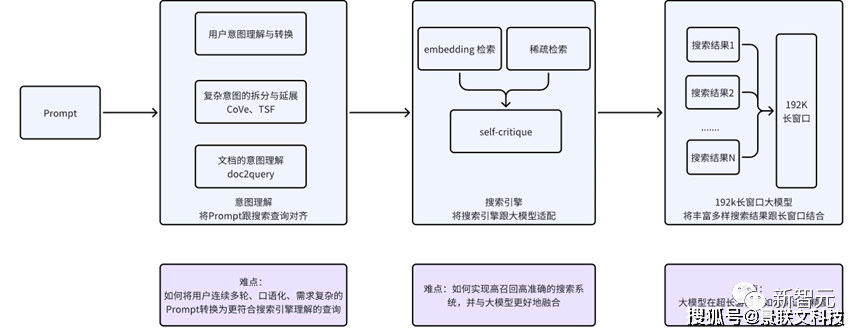
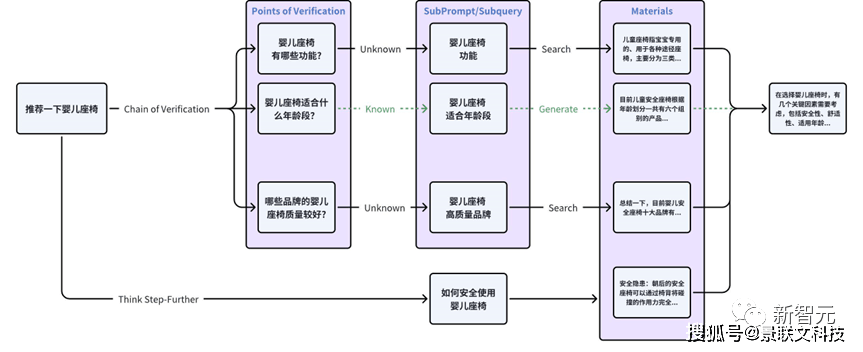
大模型时代,用户信息需求表达方式发生了巨大变化,输入方式上用户的问题不再是一个词或短句,而是变成了更自然的对话互动甚至是连续多轮对话。问题形式也更加多元,并且紧密关联上下文。输入风格上更加口语化,输入问题趋于复杂化。百川知识库意图理解,采用自主研发的百川大语言模型进行微调,能够将用户连续多轮、口语化的Prompt信息,转换为更符合传统搜索引擎理解的关键词或语义结构。通过这种方法,就能更好地桥接全新的用户需求表达与现有搜索技术之间的差距。为了应对用户的复杂需求,团队借鉴了Meta的CoVe技术,将真实场景中用户的复杂Prompt通过大模型转换并对齐,进一步拆分为多个独立、可并行检索的搜索友好型查询。并且,自主研发的TSF(Think Step-Further)技术,能够让系统洞察用户输入背后的深层问题。此外,团队还采用了一种独特的doc2prompt技术,来增强文档与Prompt之间的对齐。通过生成与文档内容紧密相关的问题Prompt,就能够提升系统对用户意图的捕捉精度,让检索结果更准确。
 点击添加图片描述(最多60个字)编辑
点击添加图片描述(最多60个字)编辑难点2:如何实现适配大语言模型的搜索系统
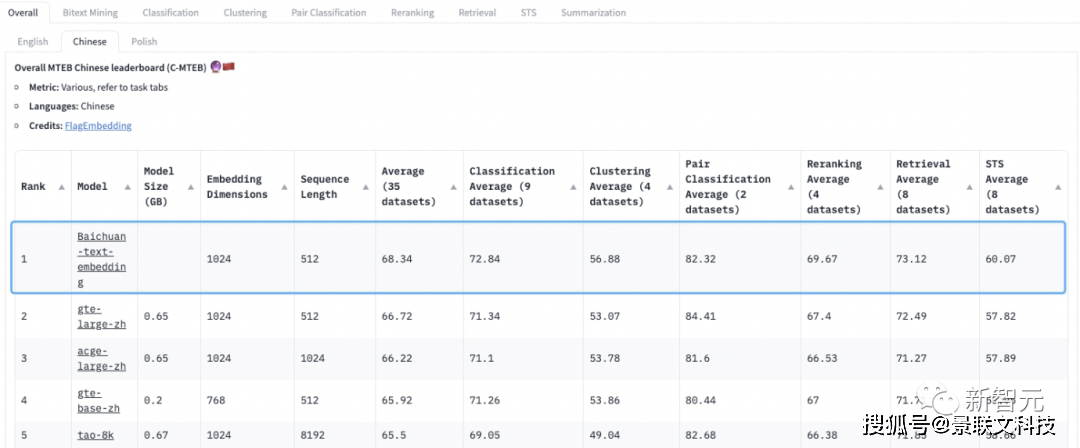
用户需求与搜索查询的匹配程度越高,大模型的输出结果越好。模型要想进一步提升知识获取的效率和准确性,除了更好的理解用户意图,还需要更强大的检索和召回解决方案。虽然借助Embedding模型,能很好地解决用户需求和知识库的语义匹配问题。但是,在知识库场景,用户的数据通常是私有化的。在这种情况下,Embeding模型就存在比较严重的退化问题,需要结合稀疏检索和Embedding模型技术实现高召回、高精度的检索系统。此外,针对搜索系统召回的结果,则需要通过搜索和大模型协同优化,来使其更好地被大语言模型所理解和应用。- 百川自研Baichuan-Text-Embedding(BCTE)模型登顶C-MTEB榜单得益于大模型领域的积累,团队使用了超过1.5T tokens的高质量中文数据进行预训练,并通过自研的损失函数,解决了对比学习对于Batchsize的依赖。最终,Baichuan-Text-Embedding(BCTE)模型在最权威的C-MTEB榜单上取得了Top 1的效果。
 点击添加图片描述(最多60个字)编辑
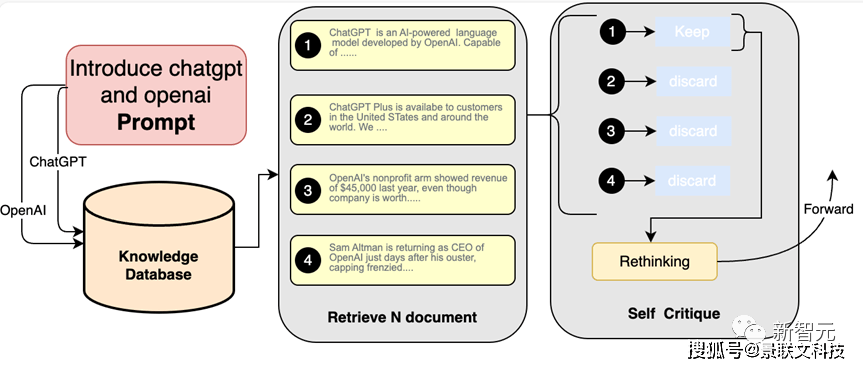
点击添加图片描述(最多60个字)编辑在C-MTEB的6个任务(分类、聚类、文本推理、排序、检索、文本相似度)上都大幅领先- 稀疏检索模型稀疏检索模型最主要的缺点,是只能做词的匹配,无法泛化到语义匹配。对此,团队将稀疏检索和Rerank模型进行了融合。相比只使用Embedding检索的开源方案(对目标文档的召回率均低于80%),效果有质的提升——未经私有化数据微调的Embedding模型可以做到86%,而在结合了稀疏检索模型后,甚至可以做到95%。- 首创Self-Critique大模型自省技术当前阶段,大模型在跟企业知识库结合的过程中,存在需求不匹配的痛点问题,因而加大了「幻觉」现象。而百川搜索增强知识库RAG在通用RAG的技术基础上,深度融合了知识库搜索,并首创了Self-Critique大模型自省技术。如此一来,大模型便可以从相关性、可用性等角度对检索内容自省,最终筛选出最优质的内容。
 点击添加图片描述(最多60个字)编辑
点击添加图片描述(最多60个字)编辑「长窗口+搜索」高效、高质量处理信息,5000万tokens回答精度95%
最初的大模型窗口普遍只有2K-8K,对开发者们带来了种种问题,比如不得不将长文本切分成非常小的片段(chunk),模型很容易忘记自己的人设和说过的话等等。百川智能在10月30日推出的Baichuan2-192K,一次可输入35万汉字,是当时全球最长上下文窗口模型,解决了知识库、长期记忆、和超长文本理解等场景问题。然而长窗口并不是万能的。单纯的长窗口模型虽然在处理大量数据时有其优势,但它在容量、成本、性能和效率方面存在明显的局限性。比如,处理超长文档时,会消耗大量tokens,大幅增加推理成本。虽然模型做到了「光速阅读」,但回答问题时每次都把所有资料从头到尾阅读一遍,也会影响效率。而长窗口+搜索增强方式能充分发挥长窗口的优势,扩大模型处理信息的能力,大幅度提高数据处理的效率和精确性。话不多说,直接看结果。目前,由海外知名AI创业者兼开发者Greg Kamradt设计的「大海捞针」(Needle in the Heystack),可以说是业内公认最权威的大模型长文本准确度测试方法。对于192k tokens以内的请求,百川智能通过长窗口+搜索增强的方式,可以实现100%回答精度。如果将测试集再增大两个数量级呢?测试结果显示,当数据集扩展到5000万tokens(大致等于9000万汉字)时,稀疏检索+向量检索的方式依然可以做到接近全域满分——实现95%的回答精度,而单纯的向量检索只能实现80%的回答精度。与此同时,百川智能的搜索增强数据库的表现也十分优秀。在博金大模型挑战赛-金融数据集(文档理解部分)、MultiFieldQA-zh和DuReader三个测试集上的得分均领先GPT-3.5、GPT-4等行业头部模型。通过「大模型+搜索」的完整技术栈,百川智能把大模型时代的内存、硬盘与网络结合做到了极致,充分发挥了成本、性能与效率的优势,为企业应用大模型提供了完整的技术解决方案。可以说,百川智能在引领国内大模型开源生态之后,再次引领行业,开启了企业定制化的新生态!
 点击添加图片描述(最多60个字)编辑
点击添加图片描述(最多60个字)编辑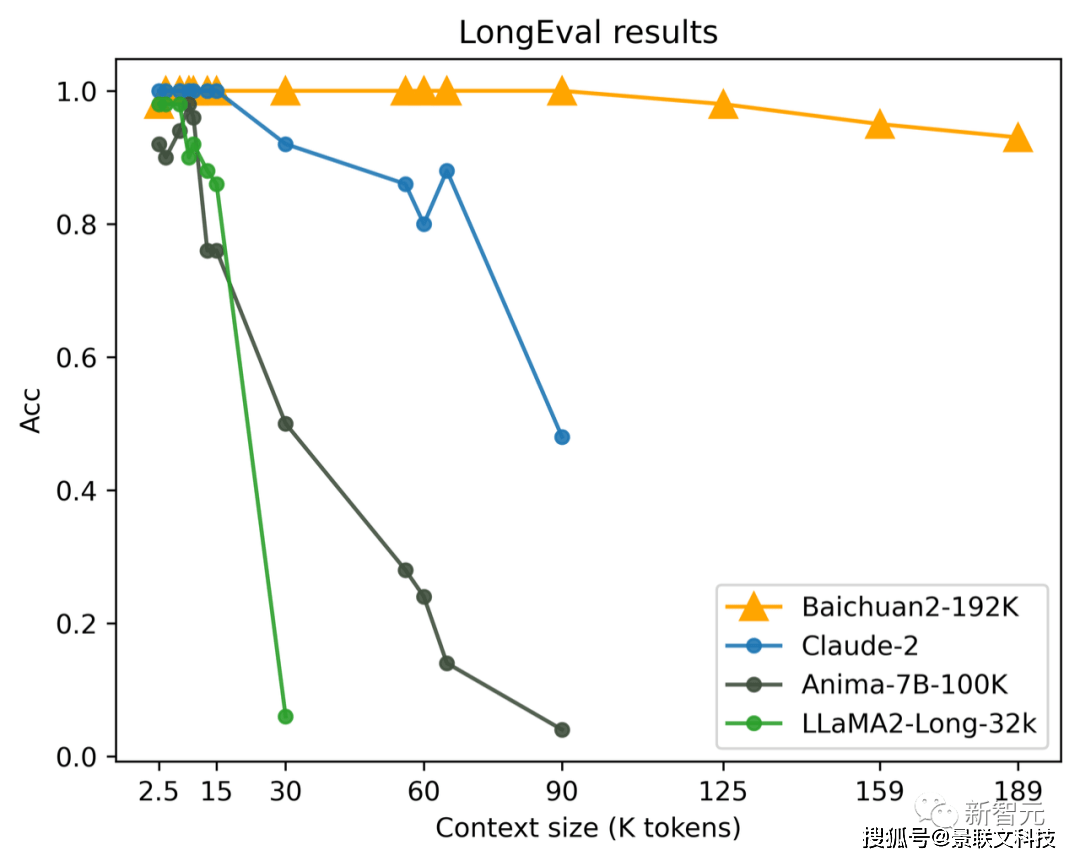 点击添加图片描述(最多60个字)编辑
点击添加图片描述(最多60个字)编辑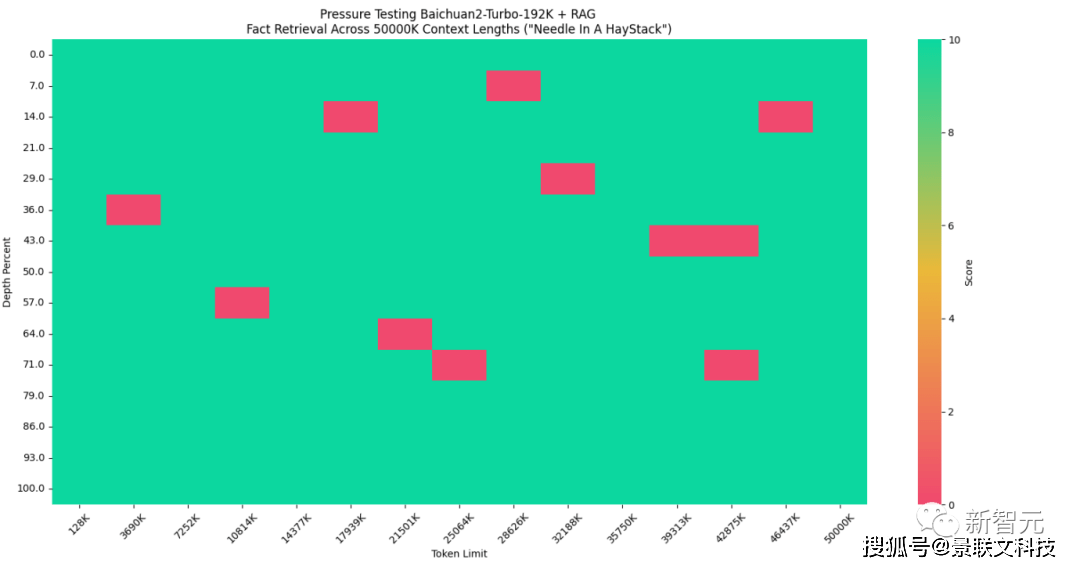 点击添加图片描述(最多60个字)编辑
点击添加图片描述(最多60个字)编辑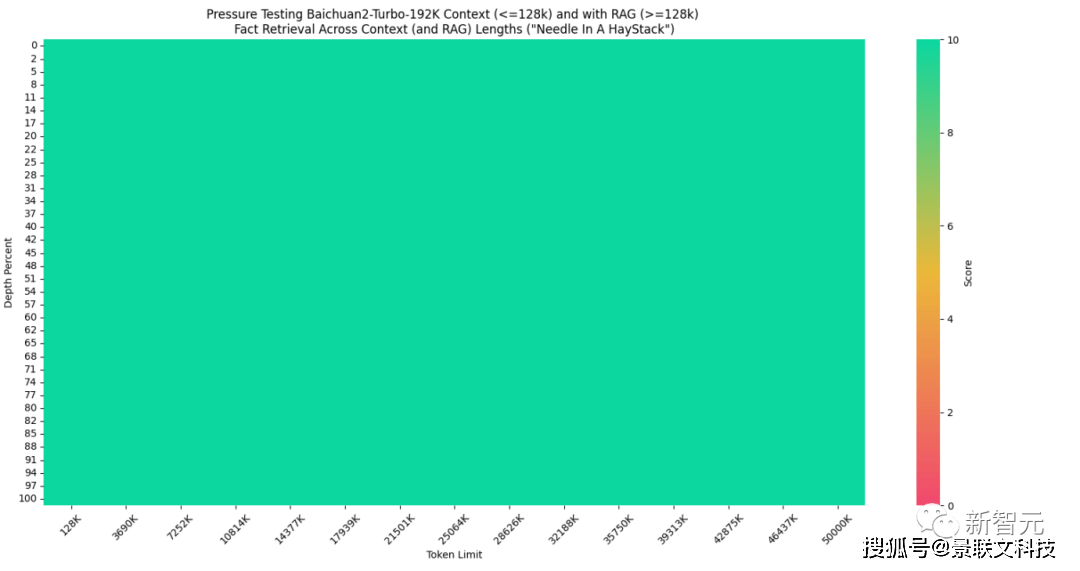 点击添加图片描述(最多60个字)编辑
点击添加图片描述(最多60个字)编辑参考资料:http://platform.baichuan-ai.com/playground
http://www.baichuan-ai.com/
