19157628936
lx@jinglianwen.com
时间:2023-06-13 11:36:33

作者:极悦注册科技

浏览: 次
SAM是Meta 提出的分割一切模型(Segment Anything Model,SAM)突破了分割界限,极大地促进了计算机视觉基础模型的发展。
SAM是一个提示型模型,其在1100万张图像上训练了超过10亿个掩码,实现了强大的零样本泛化。许多研究人员认为「这是 CV 的 GPT-3 时刻,因为 SAM 已经学会了物体是什么的一般概念,甚至是未知的物体、不熟悉的场景(如水下、细胞显微镜)和模糊的情况」,并展示了作为 CV 基本模型的巨大潜力。
SAM模概览
2023年4月6号,Meta AI公开了Segment Anything Model(SAM),使用了有史以来最大的分割数据集Segment Anything 1-Billion mask dataset(SA-1B),其内包含了1100万张图像,总计超过10亿张掩码图,模型在训练时被设计为交互性的可提示模型,因此可以通过零样本学习转移到新的图像分布和任务中。在其中他们提出一个用于图像分割的基础模型,名为SAM。该模型被发现在NLP和CV领域中表现出较强的性能,研究人员试图建立一个类似的模型来统一整个图像分割任务。
SAM 架构主要包含三个部分:图像编码器;提示编码器;以及掩码解码器。
Meta AI提出一大规模多样化的图像分割数据集:SA-1B(包含1100万张图片以及10亿个Mask图)
在这项工作中,SAM的目标是建立一个图像分割的基础模型(Foundation Models)。其目标是在给定任何分割提示下返回一个有效的分割掩码,并在一个大规模且支持强大泛化能力的数据集上对其进行预训练,然后用提示工程解决一系列新的数据分布上的下游分割问题。
项目关键的三部分包括组件:任务、模型、数据。
任务:在NLP和CV中,基础模型是一个很有前途的发展,受到启发,研究者提出了提示分割任务,其目标是在给定任何分割提示下返回一个有效的分割掩码。
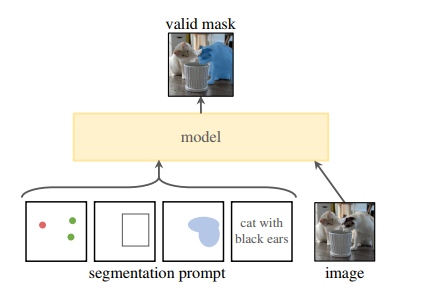

为此,研究者设计了Segment Anything Model(SAM),包含一个强大的图像编码器(计算图像嵌入),一个提示编码器(计算提示嵌入),一个轻量级掩码解码器(实时预测掩码)。在使用时,只需要对图像提取一次图像嵌入,可以在不同的提示下重复使用。给定一个图像嵌入,提示编码器和掩码解码器可以在浏览器中在~50毫秒内根据提示预测掩码。
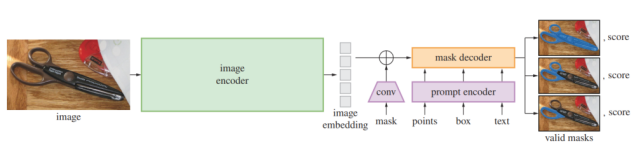
1. 图像编码器:基于可扩展和强大的预训练方法,研究者使用MAE预训练的ViT,最小限度地适用于处理高分辨率输入。图像编码器对每张图像运行一次,在提示模型之前进行应用。
2. 提示编码器:考虑两组prompt:稀疏(点、框、文本)和密集(掩码)。研究者通过位置编码来表示点和框,并将对每个提示类型的学习嵌入和自由形式的文本与CLIP中的现成文本编码相加。密集的提示(即掩码)使用卷积进行嵌入,并通过图像嵌入进行元素求和。
3. 掩码解码器:掩码解码器有效地将图像嵌入、提示嵌入和输出token映射到掩码。
掩码质量:为了评估掩码质量,研究者随机抽取了500张图像(大约5万个掩码),要求专业标注员使用像素精确的“画笔”和“橡皮擦”在模型预测掩码的基础上对其进行专业矫正。这一过程,产生成对的模型预测掩码以及人工专业矫正后的掩码。通过计算每对之间的IoU,来评估掩码质量。实现结果发现,94%的对具有大于90%的IoU。
数据引擎:为了对庞大数据的图像进行掩码标注,作者开发了数据引擎。如图所示,它是一个模型、数据的闭环系统。
模型标注数据:标注好的数据用来优化模型。以此循环,迭代优化模型以及数据质量。
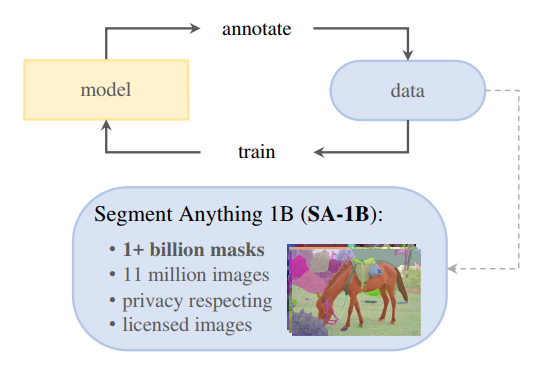
该数据引擎有三个阶段:模型辅助手动标注、半自动标注阶段和全自动阶段。
(1)模型辅助手动标注阶段
该阶段开始之前,研究者首先使用常见的公开图像分割数据集训练SAM,然后使用SAM为SA-1B数据预测图像掩码,由一组专业标注人员在预测掩码的基础上进行掩码细化。标注人员可以自由地为掩码赋予标签;此外,标注人员需要按照对象的突出程度来标记对象,并且掩码标注超过30秒就要继续处理下一张图像。在充分的数据标注后,仅使用新标注的掩码对SAM进行重新训练(该阶段总共训练了模型6次)。随着收集到更多的掩码,图像编码器从ViT-B扩展到ViT-H。同时,随着模型的改进。每个掩码的平均标注时间从34秒减少到14秒(比COCO的掩码标注快6.5倍,比2D框标注慢2倍);每个图像的平均掩码数量从20个掩码增加到44个掩码。总的来说,该阶段从12万张图像中收集了4630万个掩码。
(2)半自动阶段该阶段
其目标是增加掩码的多样性,以提供模型分割东西的能力。为了使标注者专注于不太突出的对象,首先SAM自动分割高置信度的掩码,然后向标注者展示预填充这些掩码的图像,并要求他们标注任何其他未标注的对象。该阶段在18万张图像中额外收集590万个掩码(总共1020万个掩码)。与第一阶段一样,定期在新收集的数据集上重新训练模型。每个掩码的平均标注时间回到34秒。每个图像的平均掩码数量从44个增加到72个。
(3)全自动阶段这个阶段
这个阶段的标注是全自动的,因为模型有两个主要的增强。首先,在这一阶段的开始,收集了足够多的掩码来大大改进模型;其次,在这一阶段,已经开发了模糊感知模型,它允许在有歧义的情况下预测有效的掩码。具体来说,用32x32的规则网络点来提示网络,并为每个点预测一组可能对应于有效对象的掩码。在模糊感知模型中,如果一个点位于某个部分或子部分上,模型将返回子部分、局部和整个对象。该模型的IoU模块将选择高置信度的掩码,同时选择稳定掩码(如果阈值化概率图在0.5-σ,0.5+σ)产生相似的掩码,则认为是稳定掩码。最后,在选择高置信度和稳定的掩码后,采用NMS对重复数据进行过滤。该阶段,在1100万张图像上全自动生成11亿个高质量掩码。
SAM的用途
SAM可被用于图像处理,包括软件场景、真实场景以及复杂场景。
软件场景
软件场景需要对图像编辑和修复进行操作,例如移除对象、填充对象和替换对象。然而,现有的修复工作,需要对每个掩码进行精细的注释以达到良好的性能,这是一项劳动密集型的工作。SAM 可以通过简单的提示如点或框来生成准确的掩码,可以帮助辅助图像编辑场景。
真实场景
研究者表示SAM具有协助处理许多真实世界场景的能力,例如真实世界的物体检测、物体计数以及移动物体检测场景。研究者对SAM在多种真实世界分割场景(例如,自然图像、农业、制造业、遥感和医疗健康场景)中的性能进行了评估。发现,在像自然图像这样的常见场景中,它具有优秀的泛化能力,而在低对比度的场景中,它的效果较差,而且在复杂场景中需要强大的先验知识。
除了上述的常规场景,SAM也可被用于解决复杂场景中的分割问题。研究发现,SAM在隐蔽场景中的技巧不足,潜在的解决方案可能依赖于在特定领域的先验知识的支持。
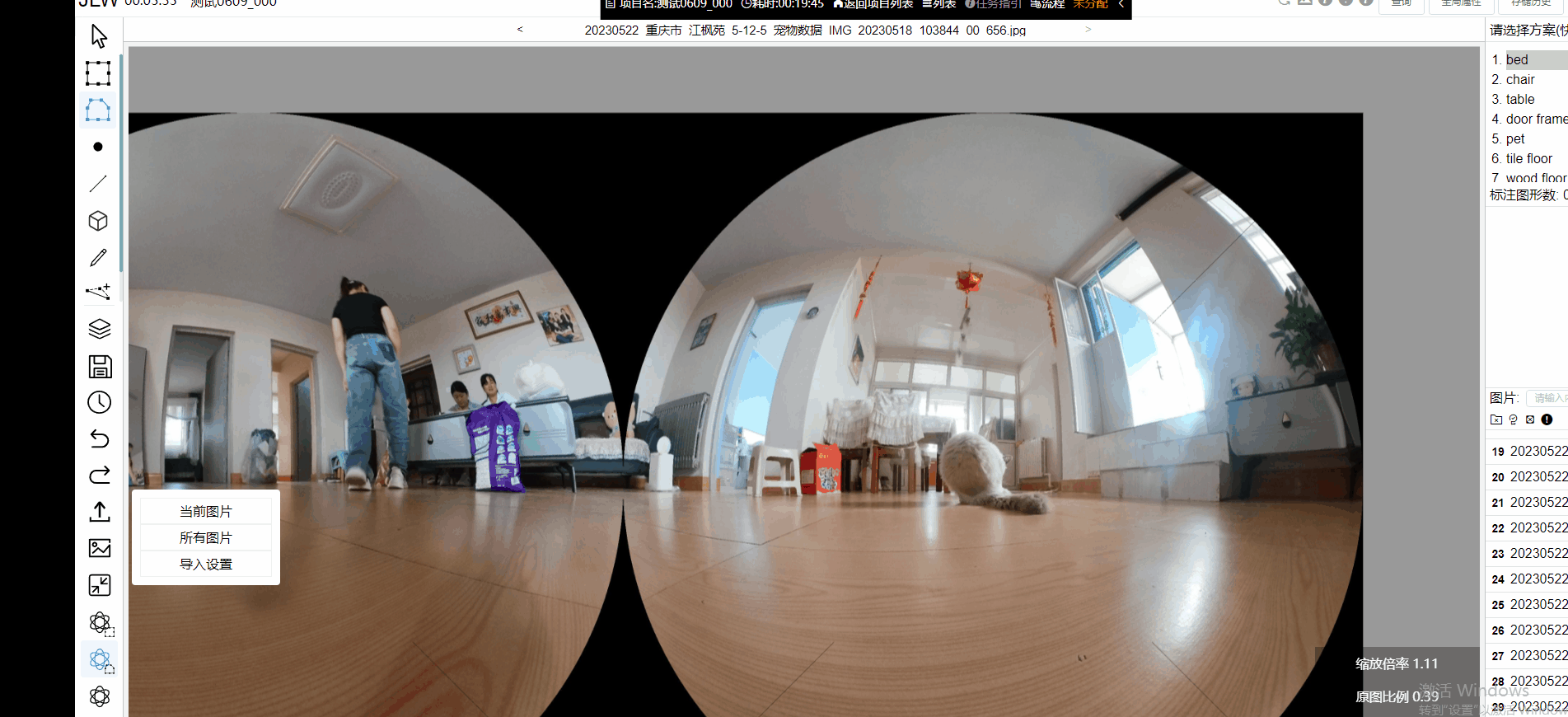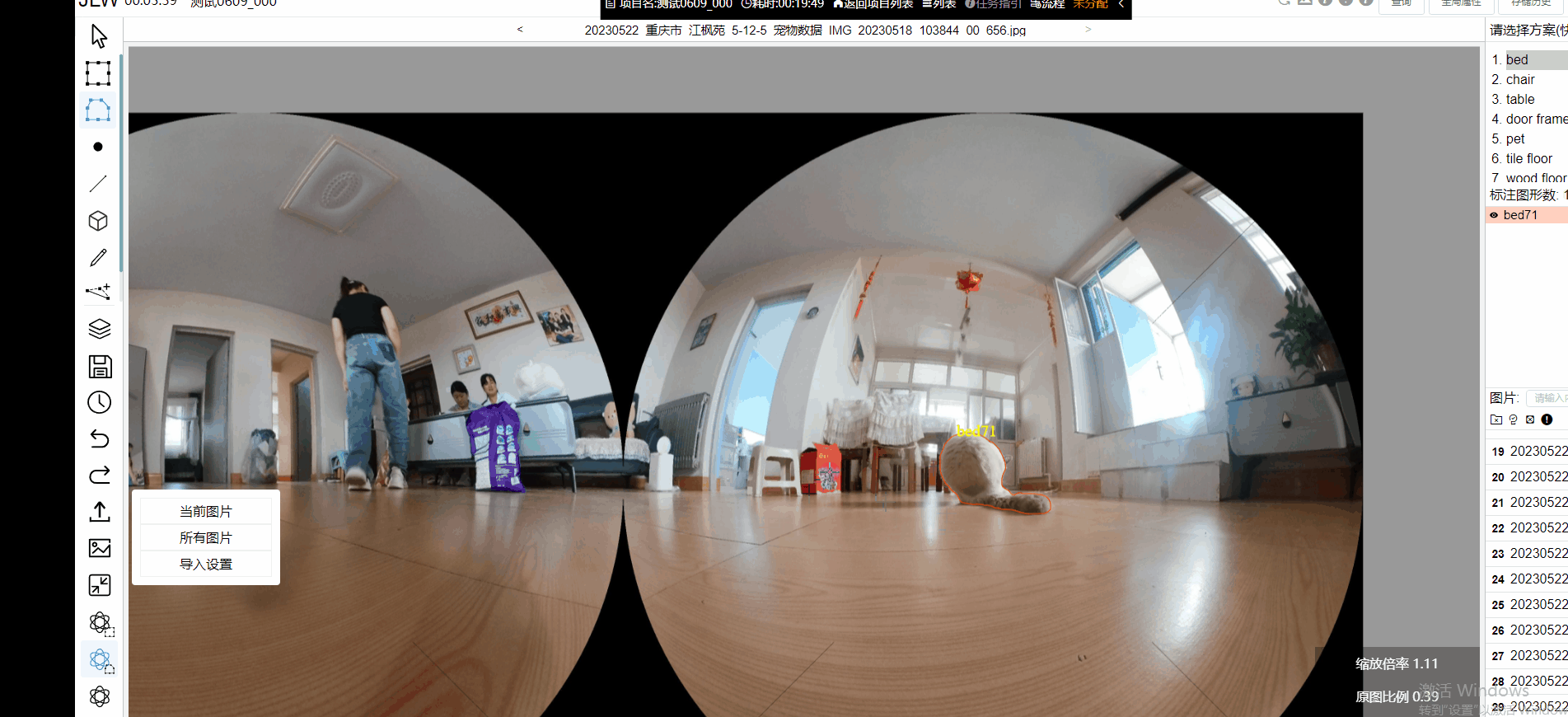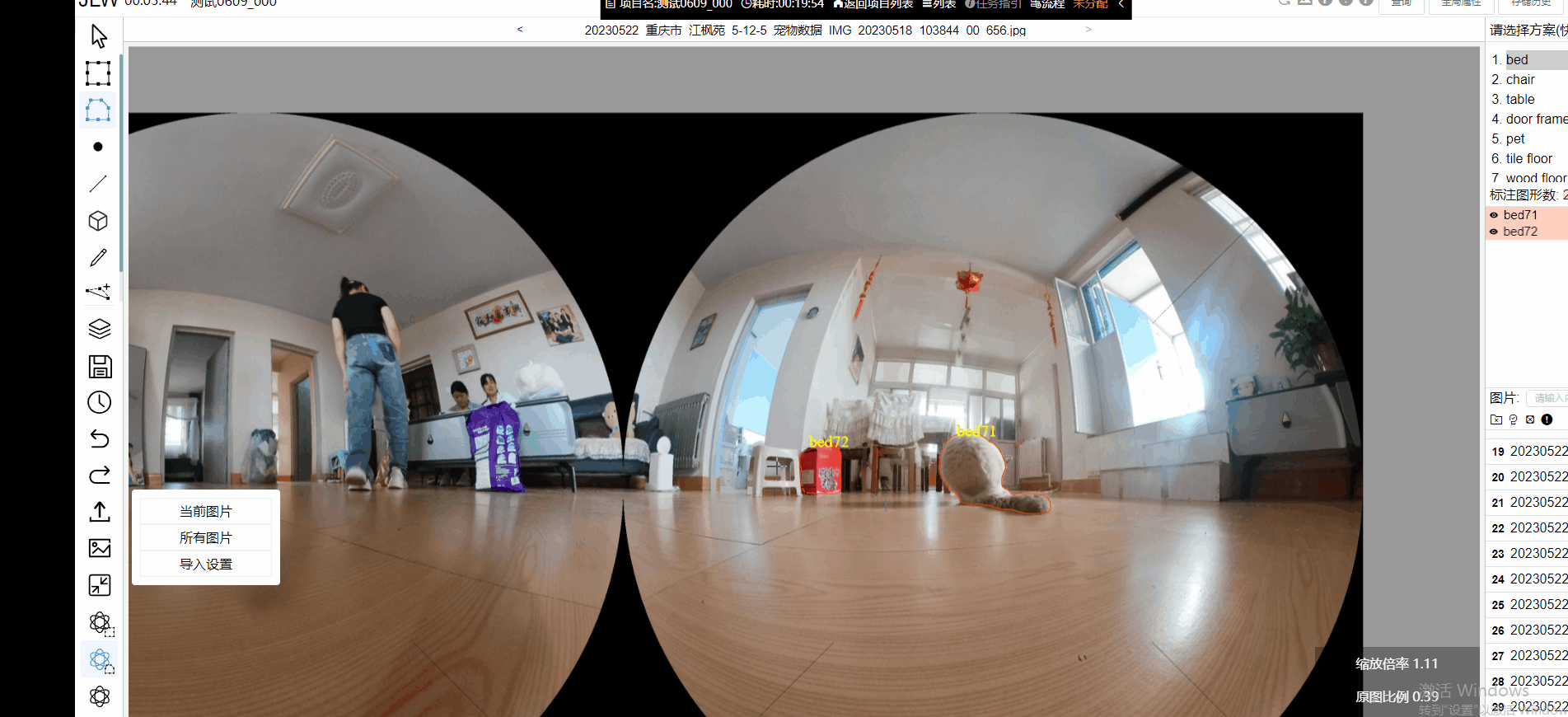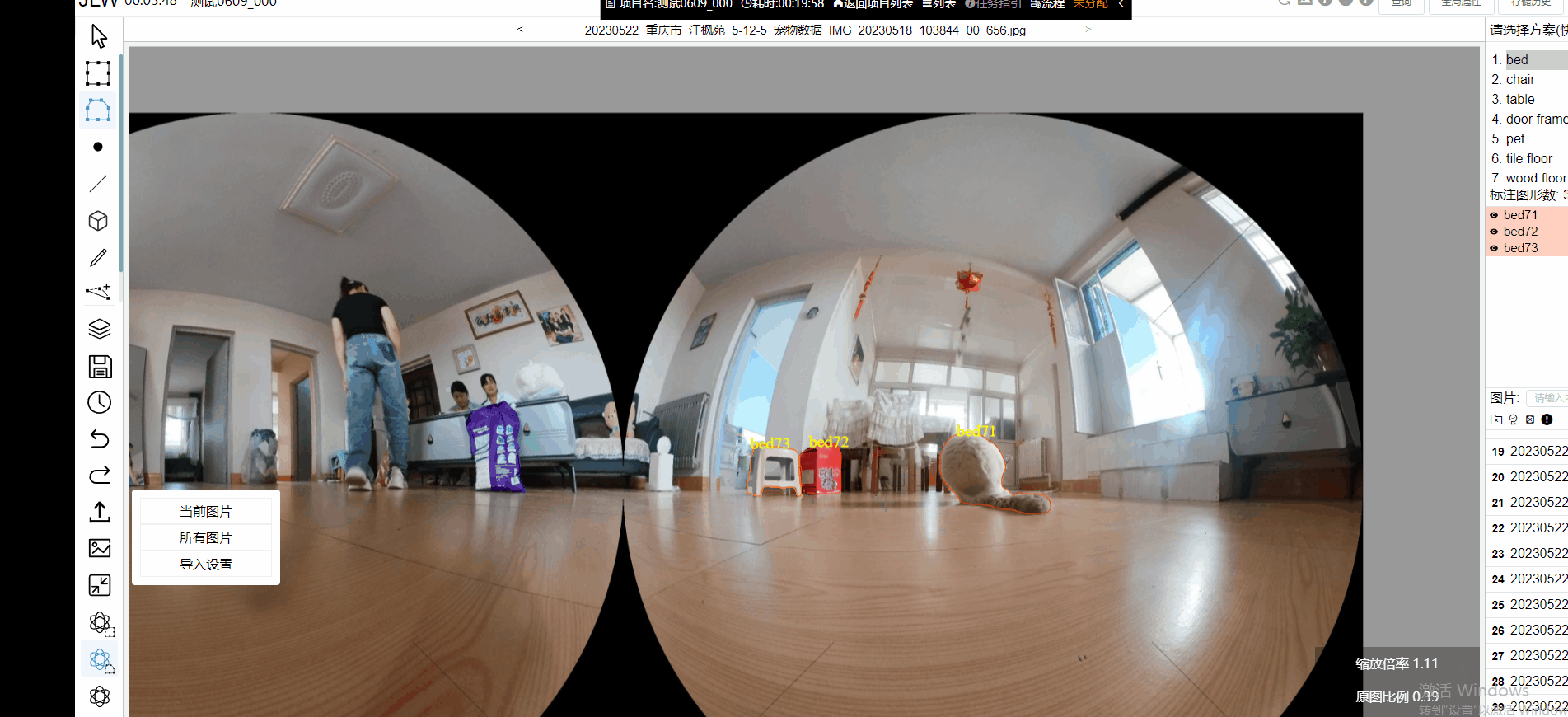
极悦注册科技是AI基础数据行业的头部企业,已通过将SAM集成进数据标注平台,为用户提供更好的标注体验。用户在使用SAM模型时,可以更加轻松、高效地完成数据标注任务,并基于SAM的特点为数据场景做了专项优化,使用户可以得到更加精准的标注结果。
此外,图像标注工作台搭载智能化辅助标注功能以提升标注效率,例如平台支持自动识别当前图片的物体类型,对识别结果自动添加品类标签,进行特征归类或分类整理;支持通过智能AI语义分割模型配合人工手动补点,可快速完成像素级图像类别的物体区域分类标注;支持对图片物体内容进行自动打点标注。此外,极悦注册数据平台还具备自动目标检测能力,可快速实现视频抽帧后图像中相同目标的跟踪和定位。

极悦注册科技数据场景实验室和数据标注基地,致力于为智能驾驶、智能家居、公共安全、智慧城市、智慧医疗、智慧金融、智能教育、智能司法等领域提供高质量、场景化的数据采集和数据标注业务,全方位支持文本、语音、图像和视频等数据类型的处理。

在数据标注平台的流程管理上,极悦注册科技重视作业协同化,可准确把控从“原始数据”到“数据成品”全流程,实现对数据标注过程的全方位把控,数据标注后经过审核、质检、验收等不同环节确保数据准确性,且每个环节都有专业人员来把控数据标注的质量和时间节点,做好各工作环节完美衔接,可以在保证质量的前提现下提高效率。此外,极悦注册科技遵循标审分离原则,风险管控机制完善,并支持平台的私有化部署,可以更好地提高数据标注的效率和精确度,全方位保证数据的隐私安全。为企业提供高效率、高质量、场景化、多维度的数据服务。
极悦注册科技|数据采集|数据标注
助力人工智能技术,赋能传统产业智能化转型升级
